그동안 열심히 만든 트레이딩 봇을 거의 완성했다. 장장 8개월간 했던 나의 엔지니어링에 대한 자랑 겸 스토리를 써보고자 한다.
Background
나는 주로 암호화폐 시장에서 차익거래와 스프레드 매매를 한다. 차익거래의 기회는 주로 유동성이 적은 시장에서 발생하기 때문에, 거래를 효율적으로 하기 위해서는 이미 존재하는 유동성을 소비하는 taker-taker 거래를 하기보다 직접 유동성을 공급하는 maker-taker 거래를 하는 것이 더 효율적이다. 이는 이제 적절한 가격 산정과 추론된 가격에 맞춘 고빈도 주문 제출이 필요해지기 때문에, 봇이 큰 도움이 된다.
내 8개월간의 엔지니어링은 주로 이 쪽에 집중하였다고 보면 된다.
첫 번째 버전: TS + CCXT + (Bun/TSX)
CCXT는 세계에 존재하는 거의 모든 거래소의 API 스펙을 TS/JS/Python/PHP로 구현한 뒤, Unified API라는 이름 하에 서로 호환되도록 레이어를 한 단계 쌓은 라이브러리이다. 어느 정도 알려진 거래소라면 매우 충실하게 구현되어 있기 때문에, 별도의 API 구현 노가다 없이 사용 가능하다는 장점이 있다.
차익거래를 하는 봇은 다음과 같은 알고리즘을 따른다.
- Maker로 유동성을 공급할 마켓과 taker로 (maker 체결이 될 때마다) 헷지를 할 마켓을 정한다.
- Taker 마켓의 호가창을 보고 유동성을 계산하여 한 번에 체결을 허용할 수 있는 양을 구한다.
- 해당 체결가와 수량으로 maker 마켓에 주문을 제출한다.
- 이 경우 maker 마켓의 호가창을 보고, 내가 ‘너무 불리한 가격’에 주문을 넣고 있지는 않은지 신경써야 한다. 예를 들어 현재 bid-ask가 5.01 @ 7.66인데 내가 6.8을 적절한 가격으로 보아도 6.8에 매도주문을 거는 것은 7.65에 넣는 것에 비해 12.5% 손해를 보는 것이다. 호가창이 “비어있으면” 바깥쪽 방향으로 매수/매도주문을 이동시키는 것이 수익을 최적화하는 데 도움이 된다.
- 일부 상황에서는 호가창을 가져오고 주문을 제출하는 사이에 가격이 변동하여 maker를 의도한 주문이 taker로 즉시 체결되었을 수 있다. 이 경우에 봇이 주문이 생기는 것을 확인할 때까지 무한정 기다릴 수 있으므로 적절한 처리가 필요하다.
- 내가 이전에 넣었던 주문과 가격이 다르면 취소하고 새 주문으로 교체한다.
- 주문이 체결되어 maker/taker 마켓의 총 포지션 합이 변동되었을 경우 taker 마켓에서 taker 주문을 제출하여 바로 헷지한다.
- 이 경우 느린 업데이트 등으로 인해 큰 포지션에 노출되었을 경우 1) 멈추거나 2) 나눠서 주문을 넣는 대응이 필요하다.
- maker/taker 마켓에서 원하는 포지션에 도달하면 루프를 멈춘다.
알고리즘의 구현 자체는 매우 쉽고 상술한 몇 가지 edge case만 고려해주면 되기 때문에(사실 위보다는 좀 더 고려할 것이 많다), 상당히 빠르게 구현을 마칠 수 있었고 실전에 투입할 수 있었다. 그런데 좀 써 보니 몇 가지 마음에 들지 않는 점이 있었다.
- CCXT는 생각보다 너무 느렸다. 이건 사실 나중에 가서 알게 된 사실인데, CCXT에 기본적으로 거래소별 1req/s의 rate limiter가 적용되어 있었고 옵션 조정을 통해 끌 수 있었다. 그래서 이 자체는 큰 문제가 되지 않았다.
- 사실 설계상으로도 문제가 있었는데, 초당 1회로 루프를 돌려서 이 때 모든 데이터(각 마켓의 호가창, 밸런스, 포지션, 현재 제출된 주문 등)를 한 번씩 받아와 처리를 한다. 입력-처리-출력의 루프가 모두 synchronous하게 돌기 때문에 효율적이지 못했다.
- 메모리 소모가 너무 컸다. 이 정도의 프로그램을 돌리는데 EC2 t4g.micro 이상 쓰고 싶지 않았지만, t4g.micro로는 봇을 두 개만 띄워도 바로 메모리 부족으로 뻗어버렸다. 특히 초반에는 별도 트랜스파일러가 필요하지 않은 Bun을 사용했는데 이 당시 Bun fetch에 메모리 누수가 있어서(…) 메모리가 줄줄 새고 있었다. 추후에 esbuild 기반의 TSX로 바꾸었지만 그래도 절대적인 메모리 사용량이 높은 것은 내 지출에 큰 영향을 끼치기 때문에 부담이 되었다.
- 주된 원인은 TS/V8 자체도 메모리를 적잖이 쓰기도 하며, CCXT가 설계상 첫 시작 때 모든 마켓의 메타데이터를 쿼리한 채로 시작하기 때문에 해당 메타데이터가 메모리에 적재된 채로 계속 남기 때문이다. 즉 TS로 CCXT를 쓰는 순간 이는 피할 수 없다.
- CCXT는
number(Python의 경우float) 타입을 주 타입으로 사용하는데, 이는 이진 부동소수점 타입이므로 십진수 계산을 할 때에는 필연적으로 오차가 발생한다. 자체적인 rounding 메커니즘이 있긴 하지만, 그래도 (CCXT 밖에서) 로그를 찍을 때 “17.89999999998에 주문 제출” 같은 로그를 보고 있자면 마음이 편치 않고 가끔 발생하는 NaN도 디버깅하기 까다로웠다.
그런 이유로, 첫 번째 봇을 돌리면서 다음 버전을 개발하기 시작하였다.
두 번째 버전: Rust + Hyper + Tower
Rust는 기본적인 런타임도 매우 가볍고, rust_decimal이라는 아주 좋은 crate가 있어서 숫자 처리가 매우 편하다.
Rust에는 API 구현체가 거의 없기 때문에, 모든 거래소를 손으로 구현해야 했고, 이를 프레임워크로 만들어서 반복적인 REST 요청을 tower로 추상화하였다. hyper가 tower::Service와의 연동이 잘 되어있어 이를 활용한 것이다.
작업물은 https://github.com/cr0sh/nerf 에 있다. 이걸 써서 바이낸스-업비트 maker-taker 전략의 PoC는 성공했으나… 결과적으로 보면 프로젝트 자체는 실패했다.
Tower 프레임워크는 본질적으로 타입 레벨 프로그래밍을 깊게 활용하는데, 기반이 타입 시스템이라는 특성상 유연성을 확보하기 어려웠다. 트레이딩은 빠른 개발 사이클을 돌리면서 유연하게 대응해야 하는데 Rust 자체가 전략 개발의 병목이 되기 쉬웠다.
세 번째 버전: Rust + Lua + Reqwest
그래서, 비교적 빠르게 개발할 수 있는 스크립트 언어로 전환하였다. 이 때 언어를 고르는 것부터 신중했는데, 다음과 같은 조건을 만족해야 했다:
- 간단해서 학습에 오래 걸리지 않을 것
- 개발 환경을 세팅하는 데 어려움이 없을 것
- 연산자 오버로드를 지원할 것: Decimal 자료형과 같은 특수 목적 타입의 연산이 편리해야 전략을 작성하기 쉽기 때문이다.
- 확장성과 Rust와의 연동이 좋을 것: 코어는 Rust로 구현하여 동적인 부분만 스크립트 언어의 유연성을 레버리지할 수 있으면 좋을 것이다. C FFI 기능이면 충분하다.
- 적당한 정도의 성능은 내 줄 수 있을 것: 아무래도 ms 단위로는 반응할 수 있어야 하다 보니(첫 구현체가 1초 단위로만 반응해서 문제가 있었다) 그 정도의 성능은 필요했다.
이를 만족하는건 LuaJIT 구현체가 있는 Lua밖에 없었다. Rust 생태계에 mlua라는 걸출한 crate가 있기도 했어서 부담 없이 선택할 수 있었다(지금은 LuaJIT C FFI만 쓰도록 mlua 의존성을 모두 걷어내었다).
결과는 매우 성공적이었다. (평일에 짬 내고 주말에 빡세게 해서) 열흘 정도만에 거래소 7개와 전략 구현을 모두 마쳤다. 지금까지도 아주 요긴하게 쓰고 있다.
기능도 아주 다양하다.
- Lua coroutine으로 async/await를 손 구현해서 여러 전략을 심리스하게 동시에 돌릴 수 있다.
- Rust side에서는 여러 개의 IP를 할당받은 머신이 request rate를 분산하면서 최신 데이터를 고속으로 가져온다.
- Lua side에서는 가져온 데이터를 asynchronous하게 받아와 변화가 있을 때에만 이벤트 루프에 메시지를 전달한다. 이를 통해 초당 수십~수백번의 쿼리를 하면서도 효율적으로 전략을 운용할 수 있다.
rust_decimal을 기본 연동하여 효율적인 십진수 계산을 지원한다.- JSON 파싱도
serde_json으로 구현하여 아주 효율적이다. (가능한 경우) 모두 zero-copy로 역직렬화하여 메모리 할당도 줄였다.- 사실 이건 잘못된 프로파일링으로 인한 과최적화였는데 들인 노력이 아까워서 그냥 쓰고 있다. ㅠ
- Observability도 좋다. Rust/Lua 사이드에서 모두
tracing을 통해 로그를 찍으며 24시간마다 rolling append되는 파일에 모두 기록되어 사후분석도 용이하다(poor man’s systemd와 같은 느낌으로). Prometheus 메트릭도 지원해서 모든 전략의 반응시간과 루프 도는 시간이 실시간으로 수집된다. 스크린샷을 보면 대부분 10ms 아래인 것을 볼 수 있다(아래 값은 모두 p-99.5 실행 시간이므로 평균은 더 낮다)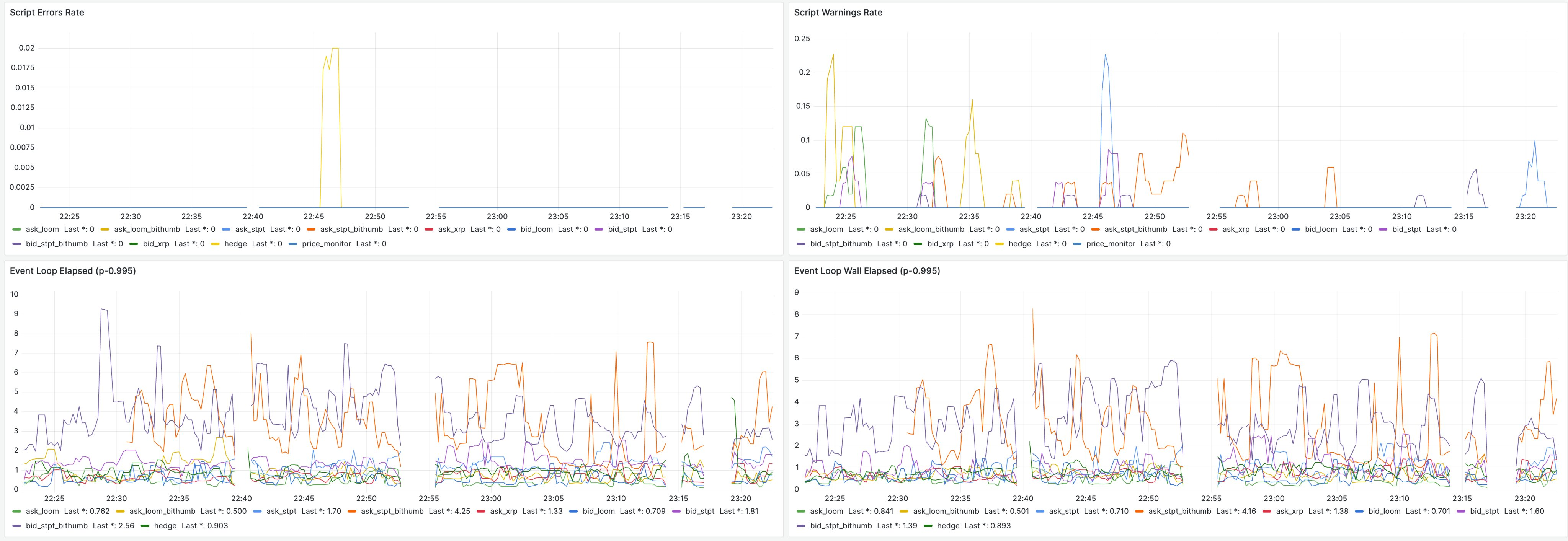
- 수집된 메트릭의 모니터링도 Grafana를 통해 수행하고, alert 조건을 만족하면 Telegram과 Twilio로 실시간 알림을 보낸다. 긴급한 경우에는 자는 사람도 깨운다(!!!)
- 결정적으로 이 모든 기능이 t4g.nano에서 아주 여유롭게 돈다!!! (메모리를 100MB도 먹지 않는다)
너무 자랑스러운 나머지 (전략을 제외한) 소스코드도 공개했다. https://github.com/cr0sh/grasshopper-public/ 별도 레포라 커밋 히스토리는 모두 잘려나갔다…
네 번째 버전: Rust + Reqwest
세 번째 버전인 grasshopper도 매우 만족스럽지만, 부족한 점이 없지는 않다. 가장 큰 문제는, Rust에서 C FFI로서 필요한 기능을 제공하는 방식이기 때문에, 만약에 .so 라이브러리에서 제공하는 기능에 부족한 점이 있으면 별도의 Rust 코딩과 인터페이스 작업을 일일히 해 줘야 한다는 것이다. 특히, 런타임에 접근하거나 복잡한 동시성 로직이 필요한 경우에는 Lua에서 컨트롤하기 쉽지 않기 때문에 그냥 Rust로 바닥부터 짜는 것이 편한 경우가 있었다(템플릿화된 차익거래가 아니라 특수한 API 또는 외부 서비스와 연동해야 하는 경우).
이런 경우를 위해, 별도의 Rust 프레임워크를 다시 만들게 되었다. 두 번째 버전에서의 실수를 막기 위해, 동적인 자료형을 최대한 활용하는 것이 주 포인트다.
- 기존에는
#[derive(Deserialize)]를 주료 활용하여 모든 API의 스키마를 코드로 표현하는 것이 큰 병목이었는데,serde_json::Value로 파싱하여 필요한 필드만 그때그때 파싱하는 방식으로 처리하는 것이 훨씬 더 구현이 쉽다는 사실을 깨닫고 이 쪽으로 전환하였다. - 대부분의 요청은 GET/POST 요청의 내용은 동일하되, private(authenticated) API의 경우 replay attack을 막기 위한 nonce+signing 매커니즘이 추가로 들어가서 매번 바뀌는 구조다. 그렇기 때문에 요청의 “본체"와 “인증” 레이어만 분리하는 식으로 분업하면 여러 API를 노가다로 구현하는 대신에 거래소별 인증 레이어만 갖추면 되어서 구현이 아주 편해진다.
- 요청의 “본체”, 즉 내용은 90%가 JSON이고 10%가 url-encoded form data로, 이 역시
serde프레임워크를 활용할 수 있다. 이를 효과적으로 처리하기 위해 인라인serde::Serialize호환 구조체를 매크로로 생성하는 방식을 썼는데 효과가 매우 좋았다(컴파일 시간이 조금 증가하지만 별 문제가 되지는 않을 것이다): https://github.com/cr0sh/exqwest/blob/8502a5e4ba34e5485bc4e321e574db3342702581/src/macros.rs
- 요청의 “본체”, 즉 내용은 90%가 JSON이고 10%가 url-encoded form data로, 이 역시
- 복잡한 동시성 로직은 모두 싱글스레드 Tokio 런타임 하에서 돌린다. 싱글스레드이기 때문에
Rc<Cell<T>>등의 자료형을 동기화 문제 걱정 없이 편하게 사용할 수 있고, 성능에도 큰 영향 없다(어차피 2코어 t4g.nano에서 돌리기 때문에). - Daemon 성격의 프로세스의 경우 하나의 프로세스에 task를 전부 합쳐서 각 프로세스가 죽을 때마다 재시작해주는 워커를 두는 식으로 해결하였다(일종의 poor man’s docker-compose 되시겠다).
이런 종류의 작업에는 (예를 들자면) 거래 내역을 로깅하고 실시간으로 알림을 보내주는 봇 등이 포함된다.
(요청/응답 부분만) 소스코드도 공개했다. https://github.com/cr0sh/exqwest
결론
8개월간 수많은 시행착오를 거치면서 트레이딩 전략을 엔지니어링하는 데 온 신경을 쏟았고, 나름의 결과를 낼 수 있었다. 트레이딩은 그 자체가 본질적으로 극도로 “애자일"하며, 전략의 경우 한 번 쓰고 버려지는 경우도 허다하기 때문에 기존에 고수하던, 신중하게 큰 설계부터 구상해 가면서 코딩하던 습관을 고치는 데에 큰 도움이 되었다. 앞으로도 트레이딩을 (지금보다는 덜 진심이겠지만) 취미로 즐겨 나가면서 본업인 학생으로 돌아가 실력을 더 키우는 데에 매진하고자 한다.